The Snooze system architecture is shown below. It is partitioned into three layers: physical, hierarchical, and client.


At the physical layer, machines are organized in a cluster, in which each node is controlled by a so-called Local Controller (LC).
A hierarchical layer allows to scale the system and is composed of fault-tolerant components: Group Managers (GMs) and a Group Leader (GL).
Each GM manages a subset of LCs and is in charge of the following tasks: (1) VM monitoring data reception from LCs; (2) Resource (i.e. CPU, memory and network) utilization estimation; (3) VM placement, relocation, and consolidation; (4) Power management; (5) Sending resource management commands (e.g. start VM, migrate VM, suspend host) to the LCs.
LCs enforce VM and host management commands coming from the GM. Moreover, they monitor VMs, detect overload/underload situations and report them to the assigned GM.In case of GM failures the LCs automatically rejoin another GM.
There exists one GL which oversees the GMs, keeps aggregated GM resource summary information, assigns LCs to GMs, and dispatches VM submission requests to the GMs. The resource summary information holds the total active, passive, and used capacity of a GM. Active capacity represents the capacity of powered on LCs, while passive capacity captures resources available on LCs in power saving state. Finally, used capacity represents the aggregated LC utilization.
GL is automatically elected among the GMs during system initialization and in case of failures. The leader election scheme is based on Apache ZooKeeper. Multicast-based heartbeat protocols are implemented at all layers to detect GL, GM, and LC failures as well as to facilitate the self-configuration and healing of the hierarchy.
A client layer provides the user interface. It is implemented by a predefined number of replicated Bootstrap Nodes (BNs) which can used by the client applications (e.g. CLI, application managers) to discover the current GL. Upon GL discovery client applications interact with the GL to start VMs. Once started they communicate with the GMs in charge to control the VM life-cycle.
High Availability
When a GL fails, its heartbeats are lost and the leader election procedure is restarted by one of the GMs. When an existing GM becomes the new leader it switches to GL mode and starts sending GL heartbeats. Other GMs receive the heartbeats and rejoin the new GL. LCs which were previously assigned to the failed GM fail to receive its GM heartbeats and rejoin the system by contacting another GM. The new GM to join is given by the assignment policy (e.g. Round robin) specified at the GL (see Administration manual for more details).
When a GM fails, its heartbeats are lost and the managed LCs rejoin the hierarchy. Moreover, GM failures are detected by the GL based on missing heartbeats, and its contact information is gracefully removed in order to prevent new VMs from being scheduled on it.
When a LC fails or is powered off, its heartbeats are lost and the GM in charge invalidates its contact information. Note, that in the event of a LC failure, its VMs are also terminated. Currently, no mechanisms exist to automatically restart failed VMs on other LCs.
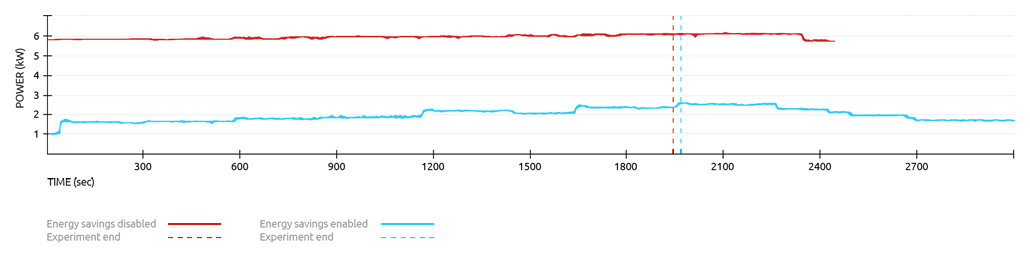
Power Consumption Chart
The following chart shows the power consumption of our experiment data center with and without energy saving features enabled. As it can be observed once enabled, Snooze scales the data center power consumption proportionally to the load.
Please refer to our latest Publications for more details. Particularly, for scalability and high availability: download. For energy management: download.